최근 참여하게 된 프로젝트의 일환의 일환(…)으로 유튜브 댓글 분석 모델링을 시작하였다.
유튜브 댓글이란 참 애매한 것으로, 모두들 황금알을 낳는 거위라도 되는 마냥 우러르지만 천천히 뜯어보는 사람의 입장에서는 생각보다 쓸데없어 보이는 경우가 많다. 지엄하신 인공지능 님이 판단하시기 전에 일개 인간이 이러쿵저러쿵 해봐야 소용 없을 듯 하지만… 어쨌든 댓글 분석은 무척 재미있다. 한 번 해 보세요.
이 포스팅에서는 문서에서 중요한 단어만을 추출하는 알고리즘인 TextRank 에 대해 다룰 것이다. 특정 기준에 맞는 유튜브 댓글만을 모아 하나의 문서처럼 취급한다면 이 댓글문서 전체에서 중요한 위치에 있는 키워드들을 추출할 수 있으리라는 가정이다. 이렇게 추출한 키워드들을 바탕으로 중요한 댓글과 중요하지 않은 댓글을 구분하는 모델을 만들 계획에 있다.
마르코프 연쇄 Markov Chain
TextRank를 이해하기 위해서는 PageRank를, 그를 이해하기 위해서는 마르코프 연쇄Markov Chain를 알아야 한다. 마르코프 연쇄를 Wikipedia에서 검색하면 다음과 같은 결과를 찾을 수 있다.

A Markov chain is a stochastic model describing a sequence of possible events in which the probability of each event depends only on the state attained in the previous event.
마르코프 연쇄는 발생 가능성이 있는 사건들이 연속적으로 일어나며, 특정 사건이 일어날 확률이 오로지 바로 이전 사건의 상태에만 의존하는 경우에 대해 말하는 확률론적 모형이다. (2020, Wikipedia)
David Poole 의 선형대수학 (Linear Algebra : A Modern Introduction, 4th edition) 에서는 마르코프 연쇄에 대해 이렇게 설명하고 있다.
(유한) 마르코프 연쇄 (…) 는 유한 개의 상태(state)들로 구성되어 서서히 변화하는 과정을 나타낸다. 각각의 단계에서 또는 시점에서, 그 과정은 상태들 중 어떤 하나에 놓여 있으며 다음 단계에서 진행은 현재 상태로 남아 있거나 다른 상태 중 하나로 바뀔 수 있다. 그 과정이 다음 단계에서 변한 상태와 그것이 일어날 확률은 과정의 과거 내력이 아니라 오직 현재 상태에만 영향을 받는다. 이런 확률을 추이확률이라 부르며 이는 상수로 가정한다. (즉, 상태 i에서 상태 j로 움직일 확률은 항상 같다.)
조금 더 이해하기 쉽도록 예를 들어 보자. A 도시와 B 도시가 있고, A에서 살던 사람들이 B로 이사갈 확률이 0.7, B에서 A로 갈 확률이 0.6이라고 하자. 이 동네에는 도시가 두 개밖에 없어서 A나 B로만 이사갈 수 있고 다른 곳으로는 갈 수 없다. A에서 B로 가지 않는다면 A에 남아 있어야 한다는 의미이다. 이를 행렬식으로 표현하면 다음과 같다.
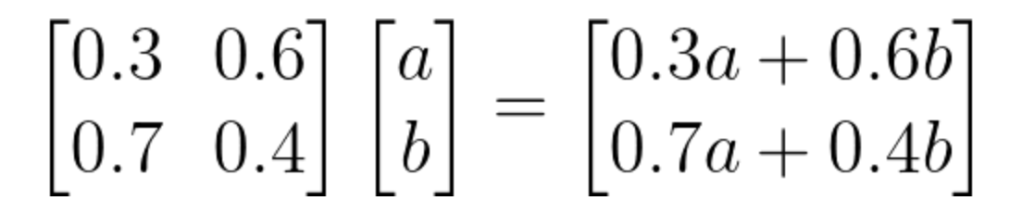
1행과 1열은 A, 2행과 2열은 B에 관한다. 즉 0.3은 A도시에서 A도시로 갈 확률 (= 떠나지 않을 확률), 0.6은 B도시에서 A도시로 갈 확률이다. 이 행렬을 추이행렬이라고 한다. 이때 한 열의 모든 확률을 더하면 1이 되므로 추이행렬의 모든 열은 확률벡터 (모든 성분이 음이 아닌 확률의 형태로 합이 1) 이다.
사람들이 이 두 도시들 사이에서 1년에 한 번씩 이사를 가거나 가지 않는다고 하자. 처음 A와 B 도시에서 살던 사람들의 수가 각각 a와 b명이라고 하면, 첫 1년이 지났을 때 A와 B 도시에 살고 있는 사람들의 수는 각각 0.3a + 0.6b, 0.7a + 0.4b 가 될 것이다. 그로부터 1년이 더 지나면 결과는 다음과 같을 것이다.
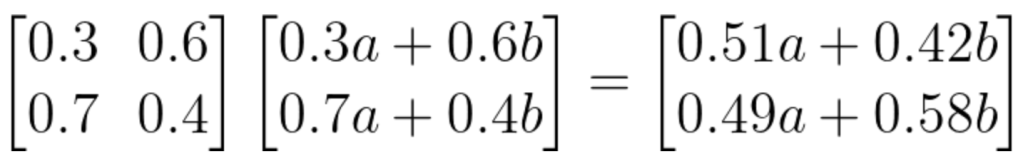
결과 벡터가 여전히 a와 b에 대해 더하면 1이 되는 확률벡터의 형태를 띠고 있는 것에 유의한다. N년이 지났을 때 두 도시에 살고 있는 사람들의 수는 확률벡터로 이루어진 추이 행렬의 N제곱 * 초깃값 (a, b)에 의해 정해진다.
이때 우리의 추이행렬을 무한히 거듭제곱하면 반드시 하나의 극한 행렬에 수렴하게 된다 (관련 논문). 이 극한 행렬과 초깃값 (a, b)를 곱하면 결국 A, B 도시에 거주하는 사람들이 더이상 이동하지 않고 안정적인 상태에 이르게 되었을 때의 인구 분포를 알 수 있다. 즉, 추이행렬을 통해 변화하는 값들이 결국 어떤 안정적인 상태에 다다르는지 알 수 있다는 것이다. 이것이 마르코프 연쇄가 대략적으로 뜻하는 바이다.
PageRank

무척 너드같이 나온 Larry Page
그렇다면 PageRank 란 무엇이고 마르코프 연쇄와 어떤 관련이 있을까? Wikipedia는 다음과 같이 설명하고 있다.
PageRank (PR) is an algorithm used by Google Search to rank web pages in their search engine results. PageRank was named after Larry Page, one of the founders of Google. PageRank is a way of measuring the importance of website pages. (…) PageRank works by counting the number and quality of links to a page to determine a rough estimate of how important the website is. The underlying assumption is that more important websites are likely to receive more links from other websites.
간단히 말하면 구글 서치 결과로 어떤 웹사이트를 제일 상위에 보여줄지를 결정하는 알고리즘으로, 페이지로 이동하는 링크의 개수와 퀄리티를 기반으로 그 페이지가 얼마나 중요한지를 판단한다. 다른 웹사이트가 많이 참조하는 웹사이트, 링크를 많이 타고 들어오는 웹사이트일수록 중요할 것이다라는 가정 하에 동작하는 알고리즘인 것이다.
이를테면 페이지 A, B, C 가 있다고 하자. A 페이지는 C 로 이동하는 링크를, B 페이지는 A, C 로 이동하는 링크를, C 페이지는 A 로 이동하는 링크를 가진다면 다음과 같은 그림으로 나타낼 수 있다.
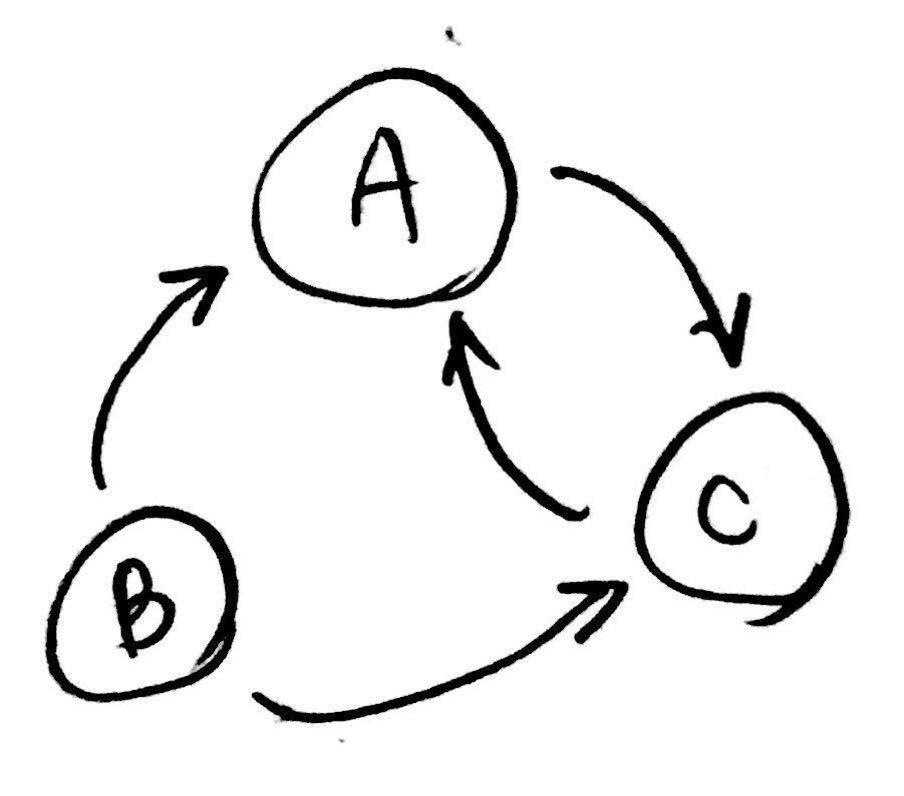
링크를 1로 나타낸다고 했을 때 페이지 A, B, C 사이의 이동을 행렬로 표현하면 다음과 같다.
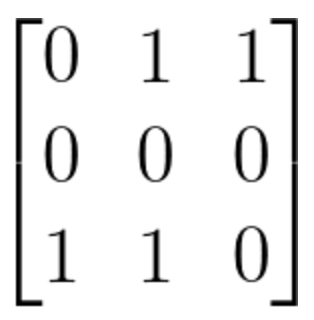
마르코프 연쇄를 적용하기 위해 이 이동 행렬을 추이행렬 (열벡터가 확률벡터인 행렬) 로 바꾸면 다음과 같다.
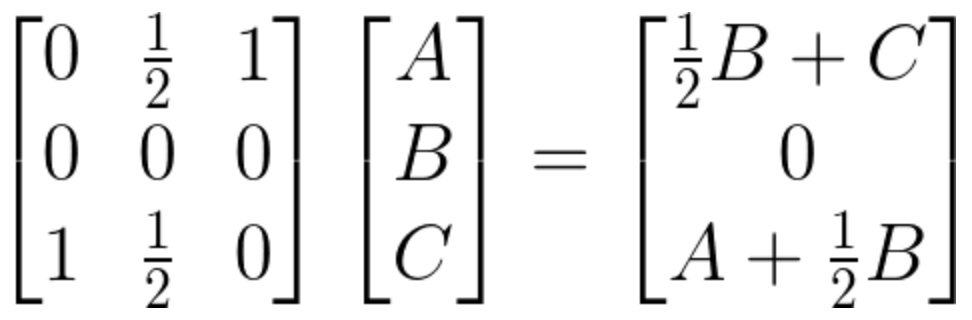
꽤나 익숙한 모양새이다. 이제 이 추이행렬을 무한히 거듭제곱하면 A, B, C 페이지의 평균적/안정적인 방문자 수를 알아낼 수 있으며, 방문자 수가 많으면 많을수록 아마 중요한 페이지일 것이다 라는 추측을 어렵지 않게 해낼 수 있다.
앞서 살펴봤던 마르코프 연쇄에 따르면 모든 추이행렬은 극한 행렬을 가지므로 추이행렬과 초깃값 벡터가 주어지면 우리는 안정 상태에 다다른 페이지의 중요도를 알아낼 수가 있게 된다. 이것이 PageRank 의 기본 원리이다.
참고로 PageRank의 실제 적용 수식은 다음과 같은데, 여태 우리가 공부한 부분이 시그마에 해당하는 내용이고 나머지는 가중치 d로 값을 보정한다는 내용이다. 타고 들어오는 링크가 하나도 없는 페이지나 다른 페이지로 이어지는 링크가 하나도 없는 페이지 등 가설에 딱 들어맞지 않는 경우를 어느정도 고려하여 페이지의 순위를 정하는 것이다. 가중치 d는 주로 0.85의 값을 갖는다고 한다.

TextRank

TextRank는 PageRank에서 파생된 알고리즘이다. TextRank는 문서에서 중요한 단어를 추출하는데, 이때 단어와 단어 사이의 연결관계를 파악하여 많은 단어들과 연관이 있는 단어일수록 문서에서 중요한 의미를 지니고 있을 것이라고 추측한다.
- 토크나이징
TextRank를 문서에 적용하기 위해서는 첫번째로 문서를 토큰화 (Tokenize) 해야 한다. 토큰화가 어떤 건지 설명하기 위해 앞서 나온 문장을 간단하게 토큰화 해 보았다.
TextRank, 는, PageRank, 에서, 파생, 된, 알고리즘, 이다, TextRank, 는, 문서, 에서, 중요, 한, 단어, 를, 추출, 하는데, 이때, 단어, 와, 단어, 사이, 의, 연결, 관계, 를, 파악, 하여, 많, 은, 단어, 들, 과, 연관, 이, 있는, 단어, 일, 수록, 문서, 에서, 중요, 한, 의미, 를, 지니, 고, 있을, 것, 이라고, 추측, 한다
말 그대로 문장을 토큰 (작은 의미의 단위) 로 나누는 일이다. 토큰화에도 다양한 방법론이 있고 알고리즘이 있기 때문에 문서의 특성을 고려하여 적절하게 토크나이저를 선택해야 한다. Python으로 쉽게 문서를 토큰화하는 방법은 KoNLPy: 파이썬 한국어 NLP 모듈을 사용하는 것으로 단계별, 특성별 다섯 가지 정도의 토크나이저 클래스를 제공하고 있기 때문에 적절한 클래스를 가져다 사용하면 된다.
유튜브 댓글의 경우 캐주얼한 단어들도 많이 들어있고 문법에 맞지 않거나 띄어쓰기가 제대로 되어있지 않은 글이 많으므로 그런 문서에 비교적 최적화되어있는 Okt 클래스를 사용하였다.
토큰화라는 것은 사실 영어보다 한국어에서 훨씬 중요하다. 우리말에는 조사와 의존명사 등 명사에 붙어서 단어의 모양을 바꾸는 품사들이 있고 동사나 형용사 등의 품사들도 규격화할 수 없을 만큼 다양한 형태로 변화하기 때문에 이를 명사면 명사, 조사면 조사, 동사나 형용사라면 원형의 형태로 떼어놓는 작업이 필수적이다. 척 봐도 ‘I am a student’ 와 ‘나는 학생이다’ 이 두 문장의 토큰화 난이도는 하늘과 땅 차이가 난다.
2. TextRank
자세한 이론적 설명은 이 페이지와 이 논문을 참조한다. 이 포스팅에서는 TextRank의 개념을 이해하고 실제로 적용하기 위한 간단한 예시만 들도록 하겠다.
한 문장이 10개의 서로 다른 단어들로 이루어져 있다고 하자. Python 리스트 형태로 표현하면 다음과 같다.
[ W0, W1, W2, W3, W4, W5, W6, W7, W8, W9 ]
window 크기가 5라고 하면 위 문장을 다음과 같이 6개의 묶음으로 나눌 수 있다.
W0, W1, W2, W3, W4
W1, W2, W3, W4, W5
W2, W3, W4, W5, W6
W3, W4, W5, W6, W7
W4, W5, W6, W7, W8
W5, W6, W7, W8, W9
각 묶음들의 단어 간 연관을 Python 튜플 형태로 나타내면 다음과 같다.
(W0, W1), (W0, W2), (W0, W3), (W0, W4),
(W1, W2), (W1, W3), (W1, W4),
(W2, W3), (W2, W4),
(W3, W4)
(W1, W2), (W1, W3), (W1, W4), (W1, W5),
(W2, W3), (W2, W4), (W2, W5),
(W3, W4), (W3, W5),
(W4, W5)
…
단어가 서로 가까이 있을수록 크게 연관되어 있고 멀리 있을수록 작게 연관되어 있으리라는 추측에 기반한다. 또 단어가 문장의 중심부에 있을수록 연관에 자주 참여하는 것을 알 수 있다.
이를 바탕으로 문장에 들어있는 서로다른 모든 토큰 (10개) 의 연관을 나타내는 10*10 행렬 g를 만든다. 예를 들면 (W2, W5)라는 튜플은 총 2번 등장하므로 g[2][5] = g[5][2] = 2가 되는 것이다. 이렇게 만든 행렬은 대칭행렬이고 (튜플의 순서가 무의미하므로), (열벡터를 확률벡터로 만드는) 정규화 과정을 거쳐 추이행렬로 만들 수 있다.
W0부터 W9까지의 모든 단어의 초깃값을 1로 두고 이를 초기벡터라 가정한다. 추이행렬의 무한 거듭제곱과 이 초기 벡터를 곱하면 단어들이 문장에서 어떤 중요도를 갖는지를 알 수 있게 된다. 문서는 수많은 문장들로 이루어져 있기 때문에 이 과정을 문장마다 반복하면 특정 단어가 이 문서 전체에서 갖는 중요도를 수치화할 수 있다.
3. 실제로 적용해보기
위키피디아의 ‘볼프강 아마데우스 모차르트‘ 항목에서 짧은 텍스트를 가져와 보았다.
볼프강 아마데우스 모차르트는 오스트리아의 서양 고전 음악 작곡가이다.
궁정 음악가였던 아버지 레오폴트 모차르트에게 피아노와 바이올린을 배웠고 그 후 요한 세바스티안 바흐의 아들로 잘 알려진 요한 크리스티안 바흐에게 작곡법과 지휘를 배웠다.
그는 35년이라는 짧은 생애 동안 수많은 교향곡 오페라 협주곡 소나타를 작곡했으며 음악 역사상 가장 위대한 작곡가 가운데 한 사람이다.
오늘날 모차르트는 음악의 신동이라는 별칭으로 불리며 널리 존경받고 있다.
4개의 문장으로 이루어져 있고 아직 토큰화는 되어있지 않은 상태이다. 모차르트, 바흐, 작곡가 등의 단어들이 반복적으로 등장하는 것을 알 수 있다. 다음과 같이 간단히 토큰화를 하고 이를 알고리즘에 집어넣어 보았다.


생각보다 ‘의’, ‘에게’, ‘이라는’ 등의 단어들의 중요도가 높게 나온다. 이런 의미없는 단어들은 사실 토큰화 과정에서 삭제하는 것이 더 좋다. 문서가 너무 짧아서 정확도가 높지는 않지만 출현 빈도가 높은 단어가 큰 중요도를 가진다는 것, 문장의 중심부에 있는 단어가 주변부에 있는 단어보다 중요하게 취급된다는 것 (‘볼프강’ 과 ‘교향곡’ 은 둘다 한 번씩 등장하지만 중요도 순위에서는 차이가 난다) 등을 알 수 있다.
